1 About algorithms
L-BFGS algorithm
Nonlinear conjugate gradient method
Comparison of L-BFGS and CG
2 Performance
Comparison of algorithms from ALGLIB
Comparison with other packages
3 Starting to use algorithm
Choosing between analytic and exact gradient
Tuning algorithm parameters
Scale of the variables
Preconditioner
Stopping conditions
Running algorithm
4 Examples
5 Downloads section
ALGLIB package contains three algorithms for unconstrained optimization: L-BFGS, CG and Levenberg-Marquardt algorithm. This article considers first two algorithms, which share common traits:
L-BFGS algorithm builds and refines quadratic model of a function being optimized. Algorithm stores last M value/gradient pairs and uses them to build positive definite Hessian approximation. This approximate Hessian matrix is used to make quasi-Newton step. If quasi-Newton step does not lead to sufficient decrease of the value/gradient, we make line search along direction of this step.
Essential feature of the algorithm is positive definiteness of the approximate Hessian. Independently of function curvature (positive or negative) we will always get SPD matrix and quasi-Newton direction will always be descent direction.
Another essential property is that only last M function/gradient pairs are used, where M is moderate number smaller than problem size N, often as small as 3-10. It gives us very cheap iterations, which cost just O(N·M) operations.
Unlike L-BFGS algorithm, nonlinear CG does not build quadratic model of a function being optimized. It optimizes function along line, but direction to explore is chosen as linear combination of current gradient vector and previous search direction:
xk+1 = xk + αkdkα is chosen by minimization of f(xk+αkdk). There are exist several formulae to calculate β, each of them corresponding to distinct algorithm from CG family. Such approach, despite its simplicity, allows to accumulate information about function curvature - this information is stored in the current search direction.
From the user's point of view these algorithms are very similar: they solve unconstrained problems, need function gradient, have similar convergence speed. It makes them interchangeable - if your program uses one algorithm, it can switch to another one with minimal changes in the source code. Both methods can be used for problems with dimensionality ranging from 1 to thousands and even tens of thousands.
However, differences exist too:
We've used following settings to compare different optimization algorithms:
In the first part of our experiment we've compared performance of ALGLIB implementations of CG and L-BFGS (with m=8). We've got following results:
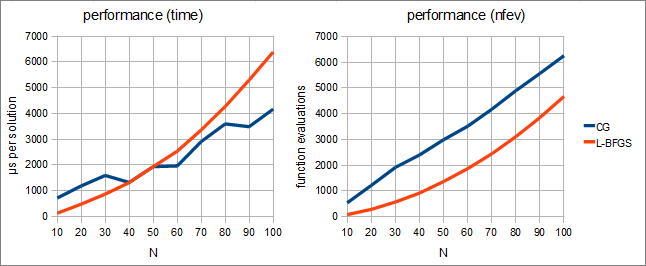
Following conclusions can be made. First, when measured in function evaluations, CG is inferior to L-BFGS. However, this drawback is important only when function/gradient are hard to compute. But if function and its gradient are easy to compute, CG will be better than L-BFGS.
In the second part of experiment we've compared ALGLIB implementation of CG with CG from GNU Scientific Library (GSL). We've used GSL 1.12 (version shipped with OS). GSL includes two kinds of CG: PR (Polak-Ribiere) and FR (Fletcher-Reeves). We've tested our implementation against CG-PR because it has somewhat better performance. On the charts below you can compare performance of ALGLIB and GSL.

ALGLIB was 7-8 times faster than GSL - both in computational time and in function evaluations. But why difference is so high? First, ALGLIB uses more efficient line search algorithm. Second, ALGLIB includes modern version of CG algorithm while GSL uses obsolete and inefficient FR and PR variants.
Just to be sure that such huge difference is not an error, we've made additional tests. Another CG algorithm from GSL (FR-CG) was even worse - ALGLIB CG was 15-20 times faster than FR-CG. We've tried to use another test function, but got similar results. Finally we've tried more stringent stopping conditions - |g|<10-14 instead of |g|<10-8. To our surprise, GSL CG failed to converge while ALGLIB CG have correctly converged.
Before starting to use L-BFGS/CG optimizer you have to choose between numerical diffirentiation or calculation of analytical gradient.
Both algorithm - L-BFGS and CG - need function gradient. For example, if you want to minimize f(x,y)=x2+exp(x+y)+y2, then optimizer will need both function value at some intermediate point and function derivatives df/dx and df/dy. How can we calculate these derivatives? ALGLIB users have several options:
Depending on the specific option chosen by you, you will use different functions to create optimizer and start optimization. If you want to optimize with user-supplied gradient (either manually calculated or obtained through automatic differentiation), then you should:
If you want to use ALGLIB-supplied numerical differentiation, then you should:
L-BFGS algorithm is quite easy to tune. The only parameter to tune is number of correction pairs M - number of function/gradient pairs used to build quadratic model. This parameter is passed to the function which is used to create optimizer object. Increase of M decreases number of function evaluations and iterations needed to converge, but increases computational overhead associated with iteration. On well-conditioned problems M can be as small as 3-10. If function changes rapidly in some directions and slowly in other ones, then you can try increasing M in order to increase convergence.
As for nonlinear conjugate gradient method, it has no tunable parameters. You just call mincgcreate function, which creates optimizer, and that's all.
Before you start to use optimizer, we recommend you to set scale of the variables with minlbfgssetscale or mincgsetscale functions. Scaling is essential for correct work of the stopping criteria (and sometimes for convergence of optimizer). You can do without scaling if your problem is well scaled. However, if some variables are up to 100 times different in magnitude, we recommend you to tell solver about their scale. And we strongly recommend to set scaling in case of larger difference in magnitudes.
We recommend you to read separate article on variable scaling, which is worth reading unless you solve some simple toy problem.
Preconditioning is a transformation which transforms optimization problem into a form more suitable to solution. Usually this transformation takes form of the linear change of the variables - multiplication by the preconditioner matrix. The most simple form of the preconditioning is a scaling of the variables (diagonal preconditioner) with carefully chosen coefficients. We recommend you to read article about preconditioning, below you can find the most important information from it.
You will need preconditioner if:
Sometimes preconditioner just accelerates convergence, but in some difficult cases it is impossible to solve problem without good preconditioning.
ALGLIB package supports several preconditioners:
ALGLIB package offers four kinds of stopping conditions:
You can set one or several conditions by calling minlbfgssetcond (mincgsetcond) function. After algorithm termination you can examine completion code to determine what condition was satisfied at the last point.
We recommend you to use first criterion - small value of gradient norm. This criterion guarantees that algorithm will stop only near the minimum, independently if how fast/slow we converge to it. Second and third criteria are less reliable because sometimes algorithm makes small steps even when far away from minimum.
Note #1
You should not expect that algorithm will be terminated by and only by stopping criterion you've specified.
For example, algorithm may take step which will lead it exactly to the function minimum - and it will be terminated by first criterion (gradient norm is zero),
even when you told it to "make 100 iterations no matter what".
Note #2
Some stopping criteria use variable scales, which should be set by separate function call (see previous section).
After creation and tuning of the optimizer object you can begin optimization using minlbfgsoptimize (mincgoptimize) function. It accepts as parameters optimizer object and callbacks which calculate function/gradient. Optimization result can be obtained using minlbfgsresults (mincgresults) function.
In order to help you use L-BFGS and CG algorithms we've prepared several examples. Because these algorithms have similar interface, for each use case we've prepared two identical examples - one for L-BFGS, another one for CG.
We also recommend you to read 'Optimization tips and tricks' article, which discusses typical problems arising during optimization.
This article is licensed for personal use only.
ALGLIB Project offers you two editions of ALGLIB:
ALGLIB Free Edition:
+delivered for free
+offers full set of numerical functionality
+extensive algorithmic optimizations
-no multithreading
-non-commercial license
ALGLIB Commercial Edition:
+flexible pricing
+offers full set of numerical functionality
+extensive algorithmic optimizations
+high performance (SMP, SIMD)
+commercial license with support plan
Links to download sections for Free and Commercial editions can be found below:




